本文共 2245 字,大约阅读时间需要 7 分钟。
Druid底层不保存原始数据,而是借鉴了Apache Lucene、Apache Solr以及ElasticSearch等检索引擎的基本做法,对数据按列建立索引,最终转化为Segment,用于存储、查询与分析。
首先,无论是实时数据还是批量数据在进入Druid前都需要经过Indexing Service这个过程。在Indexing Service阶段,Druid主要做三件事:第一,将每条记录转换为列式(columnar format);第二,为每列数据建立位图索引;第三,使用不同的压缩算法进行压缩,其中默认使用LZ4,对于字符类型列采用字典编码(Dictionary encoding)进行压缩,对于位图索引采用Concise/Roaring bitmap进行编码压缩。最终的输出结果也就是Segment。
下面,我们先讲解Druid的索引过程中的几个基本概念,再介绍实时索引的基本原理,最后结合我们在生产环境中使用过的两种索引模式加深对原理的理解。
1 Segment粒度与时间窗口
Segment粒度(SegmentGranularity)表示每一个实时索引任务中产生的Segment所涵盖的时间范围。比如设置{”SegmentGranularity” : “HOUR”},表示每个Segment任务周期为1小时。
时间窗口(WindowPeriod)表示当前实时任务的时间跨度,对于落在时间窗口内的数据,Druid会将其“加工”成Segment,而任何早于或者晚于该时间窗口的数据都会被丢弃。
Segment粒度与时间窗口都是DruidReal-Time中重要的概念与配置项,因为它们既影响每个索引任务的存活时间,又影响数据停留在Real-TimeNode上的时长。所以,每个索引任务“加工”Segment的最长周期 =SegmentGranularity+WindowPeriod,在实际使用中,官方建议WindowPeriod<= SegmentGranularity,以避免创建大量的实时索引任务。
2 实时索引原理
Druid实时索引过程有三个主要特性:
-
主要面向流式数据(Event Stream)的摄取(ingest)与查询,数据进入Real-TimeNode后可进行即席查询。
-
实时索引面向一个小的时间窗口,落在窗口内的原始数据会被摄取,窗口外的原始数据则会被丢弃,已完成的Segments会被Handoff到HistoricalNode。
-
虽然Druid集群内的节点是彼此独立的,但是整个实时索引过程通过Zookeeper进行协同工作。
实时索引过程可以划分为以下四个阶段:
Ingest阶段
Real-TimeNode对于实时流数据,采用LSM-Tree(Log-Structured Merge-Tree )将数据持有在内存中(JVM堆中),优化数据的写入性能。图3.29中,Real-TimeNodes在13:37申明服务13:00-14:00这一小时内的所有数据。Persist阶段
当到达一定阈值(0.9.0版本前,阈值是500万行或10分钟,为预防OOM,0.9.0版本后,阈值改为75000行或10分钟)后,内存中的数据会被转换为列式存储物化到磁盘上,为了保证实时窗口内已物化的Smoosh文件依然可以被查询,Druid使用内存文件映射方式(mmap)将Smoosh文件加载到直接内存 中,优化读取性能。如图3.29中所示,13:47、13:57、14:07都是Real-TimeNodes物化数据的时间点。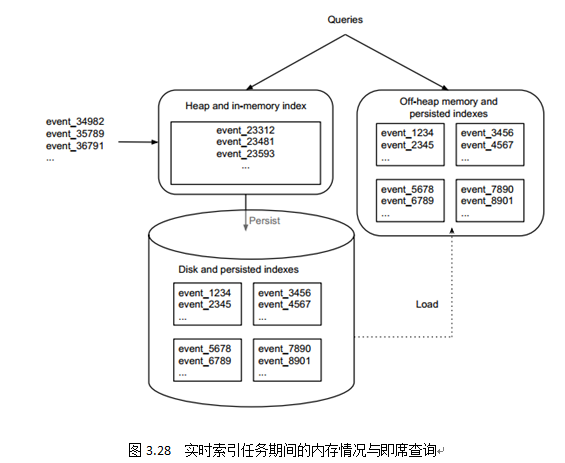
图3.28描述了Ingest阶段与Persist阶段内数据流走向以及内存情况。Druid对实时窗口内数据读写都做了大量优化,从而保证了实时海量数据的即席可查。
Merge阶段
对于Persist阶段,会出现很多Smoosh碎片,小的碎片文件会严重影响后期的数据查询工作,所以在实时索引任务周期的末尾(略少于SegmentGranularity+WindowPeriod时长),每个Real-TimeNode会产生back-groundtask,一方面是等待时间窗口内“掉队”的数据,另一方面搜索本地磁盘所有已物化的Smoosh文件,并将其拼成Segment,也就是我们最后看到的index.zip。图3.29中,当到达索引任务末期14:10分时,Real-TimeNodes开始merge磁盘上的所有文件,生成Segment,准备Handoff。Handoff阶段
本阶段主要由CoordinatorNodes负责,CoordinatorNodes会将已完成的Segment信息注册到元信息库、上传DeepStorage,并通知集群内HistoricalNode去加载该Segment,同时每隔一定时间间隔(默认1分钟)检查Handoff状态,如果成功,Real-TimeNode会在Zookeeper中申明已不服务该Segment,并执行下一个时间窗口内的索引任务;如果失败,CoordinatorNodes会进行反复尝试。图3.29中,14:11分完成Handoff工作后,该Real-TimeNode申明不再为此时间窗口内的数据服务,开始下一个时间窗口内的索引任务。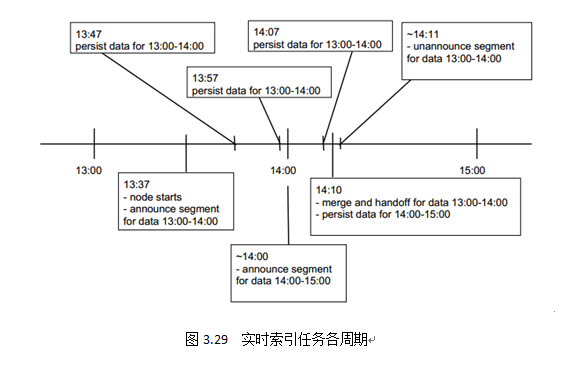
本文转自张昺华-sky博客园博客,原文链接:http://www.cnblogs.com/bonelee/p/6248832.html,如需转载请自行联系原作者